|
ГЛАВНАЯ
> Вернуться к содержанию
Cybernetics and programming
Правильная ссылка на статью:
Alekseev K.
Relational database problems
// Кибернетика и программирование.
2020. № 2.
С. 7-18.
DOI: 10.25136/2644-5522.2020.2.34076 URL: https://nbpublish.com/library_read_article.php?id=34076
Relational database problems /
Проблемы реляционных баз данных
Алексеев Константин Анатольевич
Senior Software Engineer, EPAM Systems
40-115, Польша, Silesia, г. Katowice, ул. Johna Baildona, 22d, кв. 9
Alekseev Konstantin
Senior Software Engineer, EPAM Systems
40-115, Pol'sha, Silesia, g. Katowice, ul. Johna Baildona, 22d, kv. 9

|
alxkonstantin@gmail.com
|
|
 |
|
DOI: 10.25136/2644-5522.2020.2.34076
Дата направления статьи в редакцию:
11-10-2020
Дата публикации:
30-11-2020
Аннотация:
Актуальность данной статьи заключается в том, что сегодняшние базы данных являются основой множества информационных систем. Накопленная в них информация представляет собой чрезвычайно ценный материал, и сегодня широко распространены методы обработки баз данных с точки зрения извлечения из них дополнительных методов, знаний, которые взаимосвязаны с обобщением и различными дополнительными методами обработки информации. Объектом исследования в работе являются реляционные базы данных и СУБД, предметом исследования - особенности их использования в прикладном программировании. В соответствии с поставленной целью необходимо решить следующие задачи: 1) рассмотреть понятие и сущность реляционной базы данных; 2) проанализировать проблемные аспекты реляционных баз данных в современных условиях. Реляционные базы данных являются одними из самых распространенных, благодаря своей простоте и понятности на этапе создания и на уровне пользователя. Также следует отметить, что основным преимуществом RDB является ее совместимость с основным языком запросов SQL, который интуитивно понятен для пользователей. Тем не менее, при всем разнообразии подходов все же существуют некоторые каноны, нарушение которых сильно влияет как на дизайн базы данных, так и на ее работу. Так, например, очень актуальна проблема нормализации базы данных. Пренебрежение нормализацией делает структуру базы данных запутанной, а саму базу данных ненадежной. Перспективные направления включают разработку запросов к реляционной базе данных с использованием эвристических методов, а также метод накопления ранее оптимизированных запросов с последующей проверкой выводимости текущего запроса из накопленных. Наконец, мы, скорее всего, наблюдаем очень медленный закат реляционных баз данных. Хотя они по-прежнему являются основным средством хранения информации, особенно в крупных корпоративных проектах, они постепенно заменяются нереляционными решениями, которые со временем станут большинством.
Ключевые слова:
реляционные базы данных, СУБД, кортежи, ограничения целостности данных, идентификация отношений, неопределённые значения, нормализация, денормализация, внешний ключ, основной ключ
Abstract: The relevance of this article lies in the fact that today's databases are the basis of numerous information systems. The information accumulated in them is extremely valuable material, and today database processing methods are widely spread in terms of extracting additional methods, knowledge from them, which are interconnected with generalization and various additional methods of information processing.The object of research in this work is relational databases and DBMS, the subject of research is the features of their use in applied programming.In accordance with the set goal, it is necessary to solve the following tasks:1) to consider the concept and essence of a relational database;2) to analyze the problematic aspects of relational databases in modern conditions. Relational databases are among the most widespread due to their simplicity and clarity at the creation stage and at the user level. It should also be noted that the main advantage of RDB is its compatibility with the main query language SQL, which is intuitive for users.Nevertheless, with all the variety of approaches, there are still some canons, violation of which greatly affects both the design of the database and its operation. For example, the problem of database normalization is very relevant. Neglecting normalization makes the database structure confusing and the database itself unreliable.Promising directions include the development of queries to a relational database using heuristic methods, as well as the method of accumulating previously optimized queries with subsequent verification of the derivability of the current query from the accumulated ones.Finally, a very slow decline in relational databases is probably happening. While they are still the primary storage medium, especially in large enterprise projects, they are gradually being replaced by non-relational solutions that will become the majority over time.
Keywords: relational databases, DBMS, tuples, data integrity constraints, identifying relationship, undefined values, normalization, denormalization, foreign key, primary key
1. Literature review
The leading direction in the organization of intramachine information support is the technology of banks and databases. An information database is a specialized storage of information resources in the form of an integrated set of files, which provides convenient interaction between them and quick access to data.
An information database management system (DBMS) is a set of software and language tools that provide the formation and introduction of data arrays of information. Processing and issuing the necessary information base for a group of users or management tasks is carried out using software systems for managing the information base.
The relational model was proposed by E. F. Codd in 1970 [1] as a means of structuring data information, which is based on strict mathematical principles.
The relational model requires that the data types of the information used are simple. For a relational information data model, the type of information data used is not in itself important. The requirement that the information data type be simple should be understood so that the internal structure of the information data should not be taken into account in relational operations [4]. Of course, actions that can be performed with information as a whole should be described, for example, data of a numeric type can be added, for strings, a concatenation operation is possible, etc.
The relational model is currently the most common in databases. Such scientists as R. Snodgrass, K. Jensen, J. Ben-Zvi, C. Gadia, E. McKenzie, A. Steiner contributed to the development of methods for storing and processing temporal data based on the relational model. Database research has led to a variety of relevant models [2].
2. Results
Relational systems use structures (tables) for storing and working with data. Each column (attribute) contains its own type of information. Each record in the database with a unique key is transferred to a table row, and its attributes are displayed in the table columns [3].
Each element forming a record must satisfy a certain data type (integer, date, etc.). Different RDBMSs use different types of data that are not always interchangeable.
These kinds of limitations are common in relational databases. In fact, they form the essence of the relationship.
The relational model focuses on organizing data in the form of two-dimensional tables. Each relational table is a two-dimensional array and has the following properties:
• Each element of the table is one data element
• Each column has its own unique name
• There are no identical rows in the table
• All columns in the table are homogeneous, that is, all elements in the column are of the same type
• The order of rows and columns can be arbitrary [4].
Let's give an example.
Let's say you want to create a database for an internet forum. The forum has registered users who create topics and leave messages in these topics. All this information should be placed in the database.
In theory, everything can be arranged in one table, namely:
|
Name
|
E-mail
|
Password
|
Created Topics
|
Messages created
|
|
|
|
|
|
|
|
|
|
|
|
|
However, such an arrangement is contrary to atomicity, and in the columns "Created messages" and "Created topics" an unlimited number of values are possible. It is most expedient to split the table into three:
|
Users Topics Posts
|
|
Name
|
E-mail
|
Password
|
|
Name
|
Author
|
|
Text
|
Author
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The Users table is now compliant. But the tables "Messages" and "Topics" - no, because there should not be 2 identical lines. In our case, the same user can write 2 identical messages:
|
Posts
|
|
Text
|
Author
|
|
I think we need to do this ...
|
1
|
|
I agree
|
2
|
|
And you can also do this ...
|
3
|
|
I agree
|
4
|
Note also that each post must be related to a topic. To address this issue, relational databases use keys.
Primary key (PK, primary key) - a column whose values are different in all rows. RCs are logical (natural) and surrogate (artificial) [5].
For example, for the "Users" table, the primary key can be the e-mail column, since there are no two users with the same e-mail [6].
In practice, it is recommended to use surrogate keys for storing and processing data (their use will allow to abstract the RK from real data). This is important if the user suddenly changes his e-mail, but the primary keys cannot be changed [7].
A surrogate key is an additional field in the database. Usually this is a unique id (ordinal number of the record), although the principle may be different, the main thing is uniqueness [8].
We introduce primary keys into our tables:
|
Users
|
|
User’s id
|
Name
|
E-mail
|
Password
|
|
1
|
1
|
1@gmail.com
|
4if8j3ot
|
|
2
|
2
|
2@gmail.com
|
8fdh4k5
|
|
3
|
3
|
3@gmail.com
|
F8rjr5kj
|
|
Topics
|
|
Topic’s id
|
Name
|
Author
|
|
1
|
About fishing
|
1
|
|
2
|
Bicycles
|
2
|
|
3
|
Night clubs
|
3
|
|
4
|
About fishing
|
4
|
|
Posts
|
|
Post’s id
|
Name
|
Author
|
|
1
|
I think we need to do this ...
|
1
|
|
2
|
I agree
|
2
|
|
3
|
And you can also do this ...
|
3
|
|
4
|
I agree
|
4
|
It should be noted that each record in the table is unique. All that remains is to establish a correspondence between posts and topics using the primary keys. Add one more field to the table with messages:
|
Posts
|
|
|
|
Name
|
Author
|
Topic’s id
|
|
|
I think we need to do this ...
|
1
|
1
|
|
|
I agree
|
2
|
4
|
|
|
And you can also do this ...
|
3
|
1
|
|
|
I agree
|
4
|
1
|
Now it becomes clear that the message id = 2 belongs to the topic "About fishing" (id = 4), which was created by author 1, and the rest belong to the topic "About fishing", created by author 4 (id = 1). Such a field will be called a foreign key (FK, foreign key). In this case, each value of this field is compared with some primary key from the "Topics" table. The result is a one-to-one correspondence between topics and messages.
Let's say you add a new user named author 2.
|
Users
|
|
User’s id
|
Name
|
E-mail
|
Password
|
|
1
|
1
|
1@gmail.com
|
*********
|
|
2
|
2
|
2@gmail.com
|
*********
|
|
3
|
3
|
3@gmail.com
|
*********
|
|
|
4
|
4@gmail.com
|
*********
|
How to find out which of the "2 authors" left a message? For this field "Author" in our tables "Messages" and "Topics" we will also make foreign keys:
|
Topics
|
|
Topic’s id
|
Name
|
Author
|
|
1
|
About fishing
|
1
|
|
2
|
Bicycles
|
2
|
|
3
|
Night clubs
|
3
|
|
4
|
About fishing
|
1
|
|
5
|
Who to contact
|
4
|
|
Posts
|
|
|
Post’s id
|
Name
|
Author’s id
|
Topic’s id
|
|
1
|
I think we need to do this ...
|
1
|
1
|
|
2
|
I agree
|
2
|
4
|
|
3
|
And you can also do this ...
|
3
|
1
|
|
4
|
I agree
|
2
|
1
|
So the database is ready. Schematically, it looks like this:
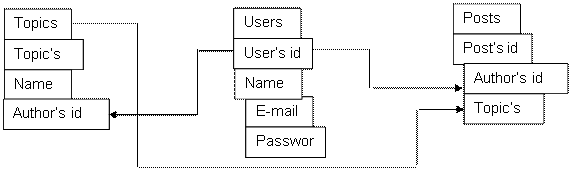
This small database has only 3 tables. Any relational database design begins with the development of a conceptual data model.
A conceptual model is understood as a reflection of the domain for the database being developed. Without going into theory, we are talking about a certain diagram with generally accepted designations: - things are designated by rectangles; - object attributes by ovals; - links in tables with rhombuses; - power and direction of bonds by arrows (single, double) [9].
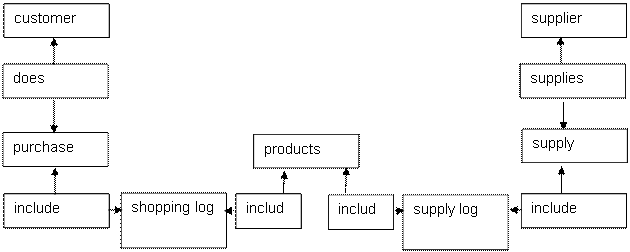
A simple example is an online store. It contains goods supplied by suppliers and ordered by customers. These are three objects and two links:
When making a delivery, the supplier confirms it with documents. Likewise with the buyer. Thus, both supply and purchase can be viewed as separate entities.
Total 5 objects and 4 links. Among them: - 2 relationships of the "one to many" type (one supplier can make several deliveries; one buyer can make several purchases); - 2 relationships of the "many-to-many" type (each delivery may include several products, and the same product may be in several deliveries; a similar situation for the "Purchase - Product" line) [10].
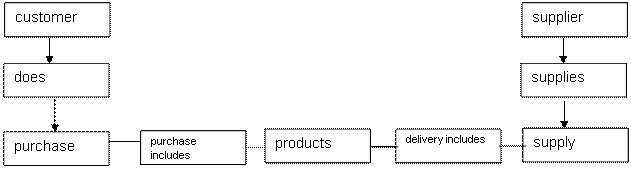
But let's remember that many-to-many relationships are not allowed in relational data models, so such relationships should be changed to one-to-many relationships. We do this by adding an intermediate object:
We see that 2 more objects have appeared in the structure - "Supply Journal" and "Purchase Journal" with "one-to-many" relationships (each magazine can include several deliveries / purchases, but each delivery / purchase includes only one magazine).
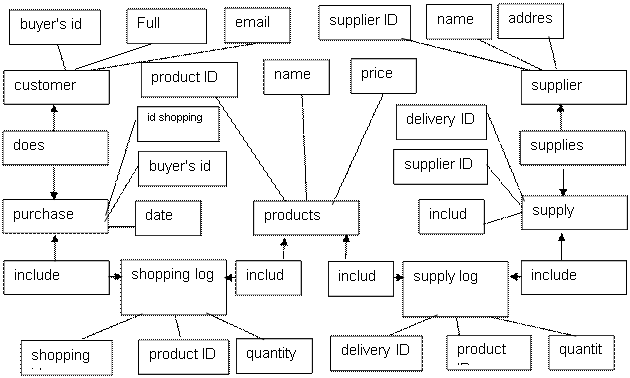
Each online store object has its own attributes:
As a result, have created a conceptual model of the future database. More precisely, we are talking only about a part of the database, since we did not take into account warehouses, employees, etc. Actually, with a vast subject area, it is better to split the data into several local areas. As a rule, the volume should be within 5-7 objects. And only after the creation of local models, they are combined into a common complex scheme. In our case, we will restrict ourselves to the created model. However, now let's convert it to a relational data model [11].
Converting a conceptual data model to a relational data model is an important part of database design. The process includes: - building a set of preliminary tables; - indication of the RK; - performing normalization.
Our objects are composed of a set of tables, and object attributes are composed of table fields:
So, we have decided on tables, fields, RK and FK. It should be noted that in the tables "Purchase journal" and "Delivery journal" RK are composite, since they consist of 2 fields.
As for normalization, it is understood as a reversible and step-by-step process, in which the original schema is changed by another schema, in which tables are characterized by a simpler and more logical structure. This is necessary for the following reasons: 1. Elimination of data redundancy [12]. Let's remember our table:
|
post’s id
|
Topic
|
Text
|
Author
|
|
1
|
About fishing
|
I think we need to do this ...
|
1
|
|
2
|
About fishing
|
I agree
|
2
|
|
3
|
About fishing
|
And you can also do this ...
|
3
|
|
4
|
Bicycles
|
I agree
|
4
|
Obviously, in the "Themes" field, the same names appear regularly. Additional memory resources are required to store such data. In addition, when duplicating data, you can make an error when entering attribute values, as a result of which the database will go into a state of inconsistency. 2. Elimination of various anomalies related to updating, deleting, modifying, etc. An example of a modification anomaly - to change the name of a topic, we will have to look at all the lines and change the name in each of them [13].
Normalization happens: - 1st normal form (1NF); - 2NF; - 3NF; - NFBC (Boyce-Codd normal form); - 4NF; - 5NF.
Each form imposes certain restrictions on data at different levels. During normalization, the database becomes stricter and less susceptible to anomalies.
If we talk about relational databases, then the minimum is 1NF. However, in the design process, DBMS specialists strive to normalize the database at least to the 3NF level, thereby eliminating data redundancy and anomalies. This is important if we strive to obtain a high-quality design result. However, a detailed description of data normalization is beyond the scope of our article, so let's just see what our base will look like at the 3NF level [14]:
|
Buyer
|
|
The supplier
|
|
Purchase
|
|
Supply
|
|
buyer's id
|
|
supplier ID
|
|
id shopping
|
|
delivery ID
|
|
Full name
|
|
Name
|
|
buyer's id
|
|
supplier ID
|
|
email
|
|
City
|
|
date
|
|
date
|
|
|
|
Address
|
|
|
|
|
|
Shopping log
|
|
supply log
|
|
product
|
|
price
|
|
id shopping
|
|
delivery ID
|
|
product ID
|
|
product ID
|
|
product ID
|
|
product ID
|
|
name
|
|
date
|
|
quantity
|
|
quantity
|
|
|
|
price
|
|
|
|
|
|
|
|
|
So, during the design process, we converted the conceptual model to a relational one. The next stage is its implementation in a specific DBMS. This will require both the DBMS itself and knowledge of the SQL language. For example, MySQL DBMS or some other DBMS is perfect.
3. The discussion of the results
Database design is a slow and time-consuming process. During design, you need to know the subject area well, take into account all the nuances. All information should be displayed in the form of elements such as objects, attributes, links, and design is successful only when everything is done as rationally as possible [15].
In general, the views on design among developers can vary. Some ignore theory, guided only by experience and common sense. Others, during the design process, assign the main role to intuition, considering design to be an art that not everyone knows. Be that as it may, knowledge is never superfluous.
Yes, a relational database is nothing more than a repository where data is stored. However, the stability of the entire application where this data is used will depend on how competently you organize it.
Relational DBMS focused on the implementation of operational data processing systems are less efficient in analytical processing tasks than multidimensional databases. This is due, firstly, to the presence of rather strict restrictions imposed by the existing implementation of the SQL language. An example of such a real-life constraint is the assumption that the data in a relational database is unordered (or more accurately, randomly ordered). At the same time, their ordering requires additional time spent on sorting each time the database is accessed. In analytical systems, data entry and selection is carried out in large portions. In turn, the data, after they enter the database, remain unchanged for a long period of time. And here it is more efficient to store data in the form of partially denormalized tables, which can store not only granular values, but also pre-computed aggregates to increase performance. And for navigation and selection, specialized addressing and indexing methods based on the assumption of low variability and low mobility of data in the database can be used. This way of organizing data is sometimes called precomputed, thereby emphasizing its difference from the normalized relational approach, which involves the dynamic calculation of various types of totals (aggregation) and the establishment of relationships between attributes from different tables (join operations).
In addition to the low efficiency, which was mentioned earlier, the disadvantages of traditional relational DBMSs can be attributed to the fact that as the main and, often, the only mechanism that provides fast search and selection of individual rows in a table (or in tables linked through foreign keys), usually various modifications of B-tree indexes are used. This solution turns out to be effective only when processing small groups of records and high intensity of data modification in databases.
Relational DBMSs may never leave the scene, but the days of their reign are definitely numbered, says Paul Creel, who published an article about it in InfoWorld in September 2011. He quotes analyst Robin Blore, who argues that the architecture of relational DBMSs is morally outdated, since it was created in the past era and does not meet modern requirements.
Relational DBMSs still dominate financial transaction processing systems, but today companies are increasingly adopting the new NoSQL architecture - scale-out, distributed, and open source. Examples of such systems are Hadoop, MapReduce, and VoltDB. According to Forrester analysts, about 75% of data in enterprises is either semi-structured information (XML, email, and EDI) or unstructured (text, images, audio and video), and only 5% of this data is stored in relational databases, and the rest - in databases of other types or in the form of files, and not subject to processing by relational systems.
In the past five years, the popularity of NoSQL databases has been growing. Initially, the term appeared in the late 90s of the 20th century. This was the name of a database created by Carlo Strozzi, which stored all data in the form of files, and instead of using SQL to access the data, it used command line scripts (shell script). However, the concept of NoSQL databases, in the form in which it is now known, was formed only in 2009. The name, which originally stood for "No SQL", that is, "Without SQL", is now interpreted as "Not only SQL" - "not only SQL", and implies that SQL support is only one of the components of the system.
Unlike relational DBMS, NoSQL is based on BASE principles [5]:
-
Basic Availability - every request is guaranteed to complete (successfully or unsuccessfully).
-
Soft State - flexible state - the state of the system can change over time, even without entering new data, to achieve data consistency.
-
Eventual Consistency - ultimately consistency - data may be inconsistent for some time, but come to agreement after a while.
Based on this, it can be understood that in NoSQL databases, speed and flexibility are more important criteria, rather than complete data integrity.
Data storage in NoSQL databases differs depending on the types:
-
Key / value store - is a hash table that contains values and their corresponding keys. For example, such tables can be used to store images or as an object cache. The most common representatives are Redis, Memcached, Riak.
-
Document-oriented databases - are used to store hierarchical data systems. In fact, they are a complicated version of the base of the previous type, allowing you to work with a stored value - read or update it only partially. Most commonly used in publishing, documentary search, or content management systems. Typical representatives are MongoDB, CouchDB, ElasticSearch.
-
Columnar databases - unlike relational databases, they store all data not in rows, but in columns. Each column is like a separate table that stores only its values, usually in sorted form. Each column is stored in a separate file. This allows efficient compression as each column contains only one data type. Typical applications for this type of DBMS are for web indexing or big data tasks, but with reduced consistency requirements. Outstanding representatives: HBase, Cassandra, Vertica.
-
Graph databases - designed for processing graphs, for example, in social networks, building routes, recommending products. Examples of such DBMS are Neo4j, OrientDB.
There are also multi-model databases that include two or more of the above categories.
From the above descriptions of the types of databases it follows that NoSQL databases are unstructured. This property of NoSQL databases allows you to make changes to the content of the database with minimal impact on the code of the project being developed. Also, the advantages of a NoSQL database include the speed of work. In addition, unlike relational databases, NoSQL databases can store data of any type (including files), while their processing speed does not decrease. [6]. Another advantage can be considered the speed of development - it does not require a large amount of preparatory actions.
Thus, you can see that both types of databases have certain advantages and disadvantages that make each of the types more suitable for a particular project. So, for storing a large amount of unstructured data, it is the NoSQL database that is suitable, since it can provide speed, easy scalability with an increase in the amount of processed data, the ability to use cloud computing and storage and easier work with it, since serious work is not needed for narrowly targeted work. knowledge. In addition, due to the lack of structure, NoSQL databases are great for projects that expand very quickly and constantly change the stored data. At the same time, you will have to sacrifice universality, since when switching to another DBMS, both relational and non-relational, you will have to create everything practically from scratch, since different NoSQL DBMSs have different APIs; the reliability of the system and the integrity of the data, since first of all the speed of work is ensured. Therefore, NoSQL databases are suitable for Big Data and document management. They are also great for working in conjunction with SQL databases as cache storage.
The more classic and familiar option is still the RDBMS. Firstly, due to its versatility, because all relational databases use SQL, therefore, if necessary, changing the used DBMS will not entail excessive labor costs. Although relational DBMSs, with the creation of which did not imply that you would have to store large amounts of data, do not have the same speed as NoSQL databases, they have greater reliability, predictability and data integrity due to the rigid definition of how exactly transactions interact with the database. The structuredness, although it is an undoubted advantage of this type of database, can also be a disadvantage in specific projects. Relational databases can be used in any projects, although in some they are inferior to NoSQL databases.
To summarize, we can say that NoSQL databases are not going to be a full replacement for relational databases. NoSQL databases implement fundamentally different paradigms of data presentation, and are designed to work in conjunction with SQL databases or in certain areas. Don't think of NoSQL as the successor to relational databases - rather as an add-on, a useful tool in certain situations.
CONCLUSION
Thus, can summarize the following.
In conclusion, I would like to note that relational databases are one of the most common, due to their simplicity and clarity at the stage of creation and at the user level. It should also be noted that the main advantage of the RDB is its compatibility with the main query language SQL, which is intuitive for users.
Nevertheless, with all the variety of approaches, there are still some canons, the violation of which greatly affects both the design of the database and its operation. So, for example, the problem of database normalization is very relevant. Neglecting normalization makes the database structure confusing and the database itself unreliable.
Promising directions include the development of queries to a relational database using heuristic methods, as well as a method of accumulating previously optimized queries, followed by checking the derivability of the current query from the accumulated ones.
Finally, we are most likely seeing a very slow decline in relational databases. Although they are still the main storage medium, especially in large enterprise projects, they are gradually being replaced by non-relational solutions, which will become the majority over time.
Библиография
1. Bordawekar R., Shmueli O. Using Word Embedding to Enable Semantic Queries in Relational Databases // Proceedings of the 1st Workshop on Data Management for End-to-End Machine Learning. ACM, 2017.S. 5.
2. Burrio N. Relational Aesthetics / Postproduction. Moscow: Ad Marginem Press, 2016.216 p.
3. Vladimirov, 20166-Vladimirov Yu.S. Leibniz-Mach relational concept // Metaphysics. 2016. No. 3 (21). S. 69-85.
4. Koznov D.V. Methodology and toolkit for subject-oriented modeling. Dissertation for the degree of Doctor of Technical Sciences, St. Petersburg State University, 2016.
5. Connolly Thomas. Databases: Design, implementation and maintenance. Theory and Practice / Connolly Thomas, Begg Carolyn. Moscow: Williams Publishing House, 2017.1440 p.
6. Kosarev D., Boulytchev D. Typed embedding of a relational language in OCaml // International Workshop on ML. 2016.
7. Krymov S.M., Leventsov V.A., Rogacheva Zh.S. Formation of relational strategies in industrial enterprises.-SPb .: Publishing house of Polytechnic. University, 2017 .--141 p.
8. Krymov S.M., Leventsov V.A. Relational strategies of modern enterprises.-SPb .: Publishing house of Polytechnic. University, 2018 .--136 p.
9. Krymov S.M., Leventsov V.A. Conceptual and methodological analysis of the dynamics of the development of relational relations at the enterprise: information model // Problems of modern economics.-2018.-No. 2.-P. 145-147. 12
10. Lednev V. Nicolas Burriot. Relational aesthetics / Postproduction: [review] // Art Studies. 2016. No. 4. S. 258-263. URL: http: // artstudies. sias. ru (date of access: 26.11.2018).
11. Li N., Bai L. Transforming fuzzy spatiotemporal data from relational databases to XML // IEEE Access. 2018.Vol. 6.P. 4176-4185.
12. Relational database and its structure [electronic resource] / Scientific library of selected natural science publications.-Access mode: http://sernam.ru/book_cbd.php?id=2 (date of access 07/11/2020).
13. Sayih M., Conrads M., Bruggemann-Klein A. Multi-client XML web applications // 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS). 2017. P. 8-12.
14. Vighio M. S., Khanzada T. J., Kumar M. Analysis of the effects of redundancy on the performance of relational database systems // 2017 IEEE 3rd International Conference on Engineering Technologies and Social Sciences (ICETSS). 2017. P. 1-5.
15. Tang P., Pitera J., Zubarev D., Chawla NV Materials Science Literature-Patent Relevance Search: A Heterogeneous Network Analysis Approach // Data Science and Advanced Analytics (DSAA), 2017 IEEE International Conference, 2017, pp. 146-154
References
1. Bordawekar R., Shmueli O. Using Word Embedding to Enable Semantic Queries in Relational Databases // Proceedings of the 1st Workshop on Data Management for End-to-End Machine Learning. ACM, 2017.S. 5.
2. Burrio N. Relational Aesthetics / Postproduction. Moscow: Ad Marginem Press, 2016.216 p.
3. Vladimirov, 20166-Vladimirov Yu.S. Leibniz-Mach relational concept // Metaphysics. 2016. No. 3 (21). S. 69-85.
4. Koznov D.V. Methodology and toolkit for subject-oriented modeling. Dissertation for the degree of Doctor of Technical Sciences, St. Petersburg State University, 2016.
5. Connolly Thomas. Databases: Design, implementation and maintenance. Theory and Practice / Connolly Thomas, Begg Carolyn. Moscow: Williams Publishing House, 2017.1440 p.
6. Kosarev D., Boulytchev D. Typed embedding of a relational language in OCaml // International Workshop on ML. 2016.
7. Krymov S.M., Leventsov V.A., Rogacheva Zh.S. Formation of relational strategies in industrial enterprises.-SPb .: Publishing house of Polytechnic. University, 2017 .--141 p.
8. Krymov S.M., Leventsov V.A. Relational strategies of modern enterprises.-SPb .: Publishing house of Polytechnic. University, 2018 .--136 p.
9. Krymov S.M., Leventsov V.A. Conceptual and methodological analysis of the dynamics of the development of relational relations at the enterprise: information model // Problems of modern economics.-2018.-No. 2.-P. 145-147. 12
10. Lednev V. Nicolas Burriot. Relational aesthetics / Postproduction: [review] // Art Studies. 2016. No. 4. S. 258-263. URL: http: // artstudies. sias. ru (date of access: 26.11.2018).
11. Li N., Bai L. Transforming fuzzy spatiotemporal data from relational databases to XML // IEEE Access. 2018.Vol. 6.P. 4176-4185.
12. Relational database and its structure [electronic resource] / Scientific library of selected natural science publications.-Access mode: http://sernam.ru/book_cbd.php?id=2 (date of access 07/11/2020).
13. Sayih M., Conrads M., Bruggemann-Klein A. Multi-client XML web applications // 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS). 2017. P. 8-12.
14. Vighio M. S., Khanzada T. J., Kumar M. Analysis of the effects of redundancy on the performance of relational database systems // 2017 IEEE 3rd International Conference on Engineering Technologies and Social Sciences (ICETSS). 2017. P. 1-5.
15. Tang P., Pitera J., Zubarev D., Chawla NV Materials Science Literature-Patent Relevance Search: A Heterogeneous Network Analysis Approach // Data Science and Advanced Analytics (DSAA), 2017 IEEE International Conference, 2017, pp. 146-154
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Рецензируемая статья посвящена рассмотрению реляционных баз данных, тему можно назвать «классической», поскольку идея использования реляционных баз данных возникла уже полвека назад. Для работы над такими темами принципиально важно как учитывать накопленный опыт обсуждения проблем, так и стремиться выявить новые аспекты хорошо знакомой специалистам темы. Рецензируемая статья, как представляется, в большей степени подводит итог рассмотрению темы, чем намечает новые её перспективы или предлагает какие-то принципиальные решения. Однако и в обсуждении хорошо известного содержания автор допускает целый ряд погрешностей, которые, думается, необходимо устранить до публикации статьи в научном журнале. Так, явно избыточными выглядят заявления о значимости баз данных в современном мире, жизнь в котором пронизана использованием информационными технологиями. Это очевидно и общепризнано, не стоит тратить на подобные заявления время и внимание читателя. Далее, в самом определении реляционных систем автор допускает элементарную формально-логическую ошибку – «круг в определении». Дело в том, что в определяющей части не должен повторяться определяемый термин, в таком случае не раскрывается содержание понятия, определения, по существу, просто не дано. Однако в статье «реляционные системы» определяются именно через использование «реляционной модели», и лишь позднее, несколько поправляя положение, автор уточняет, что в рассматриваемом случае используются двумерные таблицы, что даёт возможность читателю понять особенность рассматриваемых баз данных и последующие способы их нормализации. Далее, автор довольно поверхностно, слишком абстрактно, указывает на методы, использованные при подготовке статьи, – анализ, синтез, сравнение, наблюдение. Ну кто из авторов научных статей не использует эти простейшие методы? На специфику подхода автора и характер способов исследования указания на эти простейшие методы несколько недостаточно. Подобным же образом, говоря о результатах исследования, указывает на выявление «проблем реляционных баз данных». «Выявление проблем» не может рассматриваться в качестве научного результата, должны быть получены решения проблем, хотя бы частных. Наконец, автор допускает опечатку, отмечая цифрой два как фрагмент, в котором говорит о результатах исследования, так и их обсуждение. Скажем ещё несколько слов о структуре статьи. В целом она построена правильно, однако заключение написано явно «формально», автор не даёт читателю понять, в чём же состоит действительная значимость полученных результатов и перспективы их использования, что связано с уже отмеченными выше другими недостатками статьи. Несмотря на сделанные критические замечания статья в целом производит благоприятное впечатление. Автор проявляет достаточно широкую эрудицию и способность к анализу проблемных ситуаций. Рекомендую отправить статью на доработку. Замечания главного редактора от 27.11.2020: "Автор не в полной мере учел замечания рецензентов, но, тем не менее, статья рекомендована редактором к публикации"
Ссылка на эту статью
Просто выделите и скопируйте ссылку на эту статью в буфер обмена. Вы можете также
попробовать найти похожие
статьи
|
|